Μιας και τα hardware failures δίνουν και παίρνουν τον τελευταίο καιρό, δεν ξέφυγα κι εγώ από την ανάγκη αντικατάστασης ενός σκληρού δίσκου σε FreeBSD Server με ZFS-Only σύστημα αρχείων!
Since hardware failures are very common (to me) lately, I fell in the need of replacing one hard disc in my ZFS-Only FreeBSD Server!
Πιο συγκεκριμένα, πριν από λίγες ημέρες και ενώ ξύπνησα το πρωί και έκανα λίγο chat με τα μέλη του Chania-LUG, κάποια στιγμή το γραφικό περιβάλλον στον υπολογιστή μου πάγωσε! Η οθόνη γέμισε με πράσινες γραμμές, το ποντίκι κόλλησε και γενικά το μηχάνημα σταμάτησε να αποκρίνεται. Η πρώτη κίνηση που έκανα ήταν να μπω στο σύστημα μέσω δικτύου με ssh (από το κινητό γιατί το να στήσω laptop τα χαράματα ήταν μια διαδικασία... Αλλά αυτό δεν έχει καμιά σημασία). Είδα ότι το σύστημα είχε απόκριση, αλλά αρκετά αργή. Το ίδιο έκανα και με τον browser, όπου έλεγξα ότι ο υπολογιστής ανταποκρίνεται σε http requests κ.λ.π. Βασικά έκανα έλεγχο σε όλες τις υπηρεσίες που ήθελα να δουλεύουν. Παντού το ίδιο. Το γραφικό περιβάλλον παγωμένο με τους μπλε και πράσινους κόκκους και γραμμές, ενώ οι υπηρεσίες δουλεύαν όλες, αλλά με αρκετά μικρότερη ταχύτητα απόκρισης. Φυσικά αφού το μηχάνημα έχει και γραφικό περιβάλλον θα καταλάβατε ότι το χρησιμοποιώ και σαν desktop :P
Specifically, few days ago I woke up in the morning, had some chat with the members of Chania-LUG, and in a while the graphical environment of my PC was frozen! The screen was filled by vertical green lines, the mouse cursor was stuck to a place and didn't follow my mouse moves and the computer stopped responding. My first move was to try to ssh into the frozen computer through my network (from my cellphone because it was a little bit hard to get my laptop out of its bag early in the morning... But this has nothing to do with the story). The connection was successful, meaning that the system was up and running! I made a connection to the apache server running on the defected machine, using again my cellphone's browser and I could see the web pages served, but in a very poor and slow transfer rate. I also checked every single service that were running... the same results. Frozen graphical environment with all those blue and green spots and lines, but the services were all up and running in a slower rate. Of course, since the PC as a graphical environment you understand that I also use it as a desktop :P
Η πρώτη μου σκέψη ήταν "Μπόρα είναι θα περάσει! Κάτι κάνει το μηχάνημα από πίσω και την κάνει τη δουλειά. Το απόγευμα που θα γυρίσω σπίτι από τη δουλειά θα είναι όλα μια χαρά!" Σωστά σκέφτηκα γιατί όντως το μηχάνημα έκανε δουλειά. Για την ακρίβεια το ZFS Subsystem δούλευε για λογαριασμό μου. Για την ακρίβεια διόρθωνε και έσωζε δεδομένα που έβρισκε εσφαλμένα, εξ αιτίας του σκληρού δίσκου...
My first thought was that it was something temporary, the machine was busy on doing something and that is the reason for all the slow performance. I believed that in the afternoon, when back from my work everything will be back to normal. Well, my thought was correct... the system was busy and more specifically the ZFS Subsystem. It was trying to save data from the broken hard drive...
Το απόγευμα και αφού γύρισα σπίτι, είδα το μηχάνημα στην ίδια ακριβώς κατάσταση. Ξαναέκανα τον έλεγχο των υπηρεσιών και την έπεσα για έναν υπνάκο μιας και έβλεπα πως θα χρειαζόμουν όλες μου τις δυνάμεις για να μπορέσω να δω τι γίνεται...
In the afternoon after coming back home I found the computer in the same state. I rechecked its services and I fell in bed; I needed all my strength to find out what is really going on and to recover it...
Όταν τελικά αποφάσισα να ξεκινήσω τη δουλειά της επιδιόρθωσης του προβλήματος, κράτησα σημειώσεις για όλα όσα έκανα γιατί ήταν ευκαιρία να ξεκινήσω ένα ωραιότατο how-to. Και φυσικά, πού αλλού θα το αναρτούσα; Στην πιο κατάλληλη σελίδα του συλλόγου, την FreeBSD World. Εκεί βρίσκεται τώρα αναρτημένη η σελίδα που περιγράφει όλη τη διαδικασία της αλλαγής του ελαττωματικού σκληρού δίσκου, χωρίς να χρειαστεί εγκατάσταση του λειτουργικού από την αρχή. Η ιδιαιτερότητα είναι, φυσικά, το ZFS Filesystem. Απολαύστε την και ελπίζω να βοηθήσει αρκετά όποιον πάθει μια από τα ίδια.
When I finally decided to start working on the computer's problem I noted down all the steps I followed, as it was a very nice opportunity to make a how-to for problems like that. Hard discs fail! So, we must be prepared! And of course, this how-to is posted, where else? in FreeBSD World. There is the post that describes the whole process of changing a malfunctioned hard disc drive, without reinstalling the operating system from the very beginning. The specificity of the post is the ZFS Filesystem. The post is in Greek language, so I will translate it here. I think it is helpfull for those of you running a ZFS FreeBSD installation and have problems with the hard disc...
What's in this article
2. Time to loose our uptime... (again...)
It is time to reboot the computer... Logging in through ssh (this time from my laptop) I send the magical command...
eliaschr@pluto:~ > su
Password:
pluto# shutdown -r now
pluto#
In a while I received the normal Connection to pluto closed. message. From that point on we have to work on the defected computer only; no more network party!
When the monitor went up again and showing kernel messages I noticed some
ad0: FAILURE - READ_DMA48 status=51 error=40 LBA=383250045
ad0: FAILURE - READ_DMA48 status=51 error=1 LBA=383250045
ZFS: vdev I/O failure, zpool=zroot path=/dev/gpt/disk0 offset=191928776192 size=120320 error=5
ZFS: vdev I/O failure, zpool=zroot path=/dev/gpt/disk0 offset=191928776192 size=120320 error=5
ZFS: zpool I/O failure, zpool=zroot error=5
.
.
.
and many more of that type... The hard drive was at its last. Hmmm. Time to study ZFS Administration Handbook, to see what tools ZFS offers for cases like ours.This document is also in printed form in my library, of course... Just in case (is it one?)
What really impressed me is the fact that even with a malfunctioned hard disc the system went up! But without the graphical environment. Even through the errors in hard disc's data, ZFS used its magic and data, even then, were in a way safe! I would never imagine that!
3. Should I take a Backup?
a. Some ZFS info
Of course the answer is well known. It's time to describe some small details on helper ZFS functions on that part. Though the word "partition" is totally different from ZFS "Storage Pool Dataset", in the following text I'm going to use the word "partition" as if it has the same meaning as "ZFS Dataset". The reason is that a new ZFS user may have not distinguished the differences well enough. In that way, I believe that the text will be clearer.
The first ZFS functionality we need to know is the creation of snapshots. Snapshots are also a kind of ZFS dataset that we can mount on our system and use them in the same way as Read-Only Partitions. Their starting size is very small, just enough to hold some information for the dataset that they are a snapshot of. While we change data and files in the original dataset, ZFS stores the old data in the snapshot and then alters them in the original dataset. This means that the size of a snapshot in our hard drive is as small as possible, because it stores only the differences from the original ZFS dataset that it derives from.
The second functionality that we must be aware of (we will not use it here) is the ability of making clones. Clones can start only from a snapshot. Specifically a clone is a copy of the files of a snapshot to another part of the hard disc, together with the unchanged files that are in the ZFS dataset the snapshot comes from. So, a clone can be used as another Read/Write partition that contains all the original files of a dataset at the time we took its snapshot. In a snapshot there are only the "first release" of the altered/deleted files, while in a clone there are all the files of the snapshoted dataset. Spot that there is a snapshot to clone relationship; the snapshot is the "parent" of the clone. This relationship can be reversed if we desire. For more information about clones download and read the ZFS Administration Handbook. We will not use clones in this how-to so we won't cover clones more.
The third functionality contains the power we need and is send/receive. It is very much alike with the well known dump/restore to FreeBSD users. ZFS has the ability to send a whole dataset in a stream. That stream can be either saved as a file, or pipe it, i.e. through ssh, to a remote system. Looks very much like dump(8). What we need to say is that send can only be used in a snapshot and not in an alive dataset!
The reversed function is receive that looks alike restore(8). receive takes the data from a stream and generates a dataset. So, we could create a copy of a local dataset to a remote machine using ssh and the ZFS functions send and receive.
Armoured with those capabilities we described we can understand that ZFS provides us with a whole toolset to create a backup of our datasets; either by using clones, or by making a kind of a dump file, or even by having a remote machine with the role of a replicated backup server in case of failure of our main machine!
b. System setup
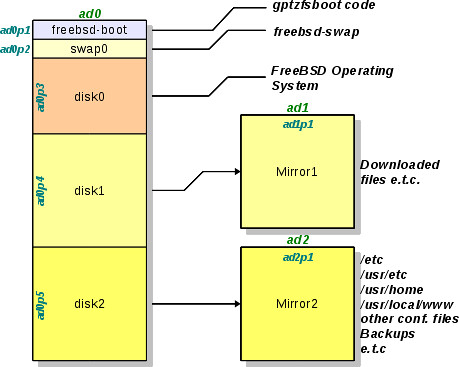
One thing we have to know is the system setup; the pools that exist in our system. In that way we can explain the state of the computer to find out what is going on. At the same time we will explain the reasons we decided to use this kind of real estate at the storage pools. The hard discs contained in the computer are one 1.5TB and two 500GB. The following diagram can bring some light and help us explain the whole setup:
In the diagram the partitions of the hard discs are presented. In those disc partitions there will be the ZFS Storage Pools. The partitioning scheme is GPT and not the ordinary old geom(4).
The first 500GB of the hard disc are used for the operating system. Here there are the following partitions:
- ad0p1: Boot Partition for the bootloader of the operating system. It has small size, 256KB are enough. Its partition type is freebsd-boot and contains the code of gptzfsboot.
- ad0p2: Swap Partition for the virtual memory space of our operating system. Its size is 4GB and its type is freebsd-swap. The name of the partition is swap0
- ad0p3: Here lies our operating system. The size of the artition is the rest of the first 500GB of the hard disc. Since there will be the ZFS Storage datasets, its type is freebsd-zfs.
In the last big part (the operating system's one) there are information that don't need to be mirrored. A failure in the operating system's part just needs another installation and nothing more.
There are other two big partitions on the disc of 1.5TB and they are both of size 500GB. These two partitions (ad0p4 and ad0p5 respectively) are mirrored by the two other hard discs of size 500GB each (ad1p1 and ad2p1 respectively). The reason that we do this mirroring is to have an automatic backup of our data to the other physical devices. In that way, whatever lies in partition ad0p4 it is also written in the hard disc ad1 and whatever lies in ad0p5 it is also written automatically in hard disc ad2.
One of the reasons we decided to use this configuration is the easiness of finding 500GB devices in a low price. So, it's a tactics we can use to be able to recover easily our system. At the same time, if a hard disc fails (which is the reason for this article's existance :)) then it is better to loose only 500GB of data than more (of course the best thing is not to loose a single bit, but...). In our case, the malfunctioned disc is, which one according to Murfy's Law, ad0 with capacity of 1.5TB. But even in that case the configuration we followed saved our data.
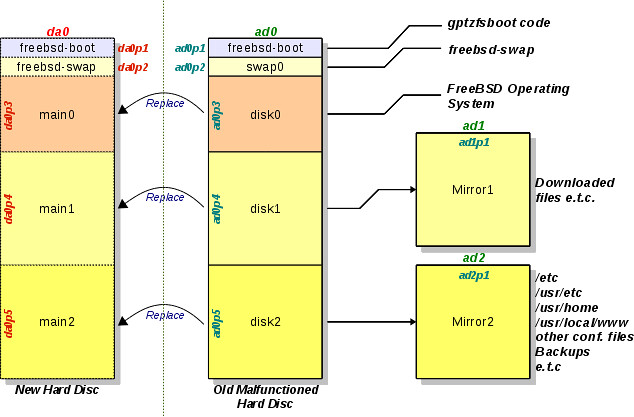
In order to be able to recover our system we need to have a new device of 1.5TB, that we will connect to the system externally on a USB. That means that the name of the new device will be da0. The following diagram presents the partitioning of the new hard drive and its relationship to the old malfunctioned one.
In the diagram the partitions are designed using dashed lines. This means that they do not exist and we have to create them. Don't forget that the new hard drive da0 is brand new.
Also, in the same diagram we can see that the partitions need to be copied are only three, ad0p3, ad0p4 and ad0p5. This is true because there is no need to copy neither the swap data, nor gptzfsboot code. The latter will be written in the new hard drive from the very beginning.
c. Check and data recovery
To be able to backup our data we must ensure that they are safe and correct. Only root user can perform such operations. Lets first check the state of the available ZFS Pools:
eliaschr@pluto:~ > su
Password:
pluto# zpool status -v #it could be -x as well
pool: Common1
state: ONLINE
status: The pool is formatted using an older on-disk format. The pool can
still be used, but some features are unavailable.
action: Upgrade the pool using 'zpool upgrade'. Once this is done, the
pool will no longer be accessible on older software versions.
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
Common1 ONLINE 0 0 0
mirror ONLINE 0 0 0
gpt/disk1 ONLINE 0 0 0
gpt/Mirror1 ONLINE 0 0 0
errors: No known data errors
pool: Common2
state: ONLINE
status: The pool is formatted using an older on-disk format. The pool can
still be used, but some features are unavailable.
action: Upgrade the pool using 'zpool upgrade'. Once this is done, the
pool will no longer be accessible on older software versions.
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
Common2 ONLINE 0 0 0
mirror ONLINE 0 0 0
gpt/disk2 ONLINE 0 0 0
gpt/Mirror2 ONLINE 0 0 0
errors: No known data errors
pool: zroot
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://www.sun.com/msg/ZFS-8000-9P
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
gpt/disk0 ONLINE 198 0 0
errors: No known data errors
pluto#
Here we can see that the pool experienced unrecoverable error is the one that has contains the operating system, zrootTime to let ZFS to try to check the pool and recover whatever errors it can handle. This is how it is done:
pluto# zpool scrub
pluto# zpool status -v
pool: Common1
state: ONLINE
status: The pool is formatted using an older on-disk format. The pool can
still be used, but some features are unavailable.
action: Upgrade the pool using 'zpool upgrade'. Once this is done, the
pool will no longer be accessible on older software versions.
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
Common1 ONLINE 0 0 0
mirror ONLINE 0 0 0
gpt/disk1 ONLINE 0 0 0
gpt/Mirror1 ONLINE 0 0 0
errors: No known data errors
pool: Common2
state: ONLINE
status: The pool is formatted using an older on-disk format. The pool can
still be used, but some features are unavailable.
action: Upgrade the pool using 'zpool upgrade'. Once this is done, the
pool will no longer be accessible on older software versions.
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
Common2 ONLINE 0 0 0
mirror ONLINE 0 0 0
gpt/disk2 ONLINE 0 0 0
gpt/Mirror2 ONLINE 0 0 0
errors: No known data errors
pool: zroot
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://www.sun.com/msg/ZFS-8000-9P
scrub: scrub completed after 23h20m with 0 errors on Mon Oct 18 23:54:39 2010
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
gpt/disk0 ONLINE 249 0 0 256K repaired
errors: No known data errors
pluto#
After many hours of hard work, ZFS made its miracle! It recovered all the errors it found.
d. Data backup
To backup our data we need to follow two steps. The first is to make a snapshot of the datasets we want to backup and then we need to create the backup file fro the snapshot. The best way to do the latter in a mulfunctioned system is the ZFS send:
pluto# zfs list
NAME USED AVAIL REFER MOUNTPOINT
Common1 274G 182G 274G /Common
Common2 224G 233G 18K /Common2
Common2/Backups 73,1G 233G 73,1G /Common/Backups
Common2/Datasheets 7,43G 233G 7,43G /Common/Datasheets
Common2/Documentation Section 3,22G 233G 3,22G /Common/Documentation Section
Common2/ECh Documents 21,4G 233G 21,4G /Common/ECh Documents
Common2/Pictures 13,4G 233G 13,4G /Common/Pictures
Common2/home 105G 233G 105G /usr/home
Common2/www 275M 233G 275M /usr/local/www
zroot 107G 346G 221M legacy
zroot/tmp 380M 346G 380M /tmp
zroot/usr 19,5G 346G 14,6G /usr
zroot/usr/ports 4,64G 346G 270M /usr/ports
zroot/usr/ports/distfiles 4,38G 346G 4,38G /usr/ports/distfiles
zroot/usr/ports/packages 18K 346G 18K /usr/ports/packages
zroot/usr/src 303M 346G 303M /usr/src
zroot/var 2,32G 346G 13,5M /var
zroot/var/crash 1024M 346G 1024M /var/crash
zroot/var/db 1,15G 346G 1,09G /var/db
zroot/var/db/pkg 58,6M 346G 58,6M /var/db/pkg
zroot/var/empty 18K 346G 18K /var/empty
zroot/var/log 92,4M 346G 92,3M /var/log
zroot/var/mail 200K 346G 200K /var/mail
zroot/var/run 130K 346G 111K /var/run
zroot/var/tmp 67,3M 346G 67,3M /var/tmp
pluto# zfs snapshot -r zroot/var@2010-10-20
pluto# zfs snapshot -r zroot/tmp@2010-10-20
pluto# zfs snapshot -r zroot/usr@2010-10-20
pluto# zfs snapshot zroot@2010-10-20
pluto# zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
zroot@2010-10-20 98K - 221M -
zroot/tmp@2010-10-20 0 - 380M -
zroot/usr@2010-10-20 326K - 14,6G -
zroot/usr/ports@2010-10-20 0 - 270M -
zroot/usr/ports/distfiles@2010-10-20 0 - 4,38G -
zroot/usr/ports/packages@2010-10-20 0 - 18K -
zroot/usr/src@2010-10-20 0 - 303M -
zroot/var@2010-10-20 21K - 13,5M -
zroot/var/crash@2010-10-20 0 - 1024M -
zroot/var/db@2010-10-20 156K - 1,09G -
zroot/var/db/pkg@2010-10-20 0 - 58,6M -
zroot/var/empty@2010-10-20 0 - 18K -
zroot/var/log@2010-10-20 85,5K - 92,3M -
zroot/var/mail@2010-10-20 0 - 200K -
zroot/var/run@2010-10-20 19K - 111K -
zroot/var/tmp@2010-10-20 0 - 67,3M -
pluto#
Snapshots are ready. Don't forget that snapshots are like partitions and can be mounted like any other partition. The only difference is that they contain only the old version of the files altered since the making of the snapshot and indexes to the unaltered ones.
Now we need to create copies of the snapshots but having all the files (not indexes). The real problem is the destination of the copies. If we connect an external drive at computer's USB then it is more likely that it will be formated using FAT32 or NTFS filesystem. FAT32 has the problem of maximum file size of 4GB. This is not appropriate for our situation because the data we need to backup are more than this maximum file size... In contrary NTFS can handle very large files but in FreeBSD fuse-ntfs is very unstable. It is very easy to have problems during writing to NTFS and have a very beautiful kernel core dump! So, we avoid using it.
The solution is our internal mirrored setup. The good thing about the existence of two mirrors is that the same data are in two hard discs at the same time. So, if one of them starts failing during a write cycle, ZFS knows well how to handle then and to keep the correct ones using the mirrored drive. Alternatively, we could run a ssh server in a remote machine in our network and send the backup there. There are solutions for everybody's taste! :P
Time for the real backup:
pluto# zfs send -Rv zroot/usr@2010-10-20 > /Common2/usr.20101020
.
.
.
pluto# zfs send -Rv zroot/tmp@2010-10-20 > /Common2/tmp.20101020
.
.
.
pluto# zfs send -Rv zroot/var@2010-10-20 > /Common2/var.20101020
.
.
.
pluto# zfs send -v zroot@2010-10-20 > /Common2/root.20101020
.
.
.
pluto# ls -l /Common2
-rw-r--r-- 1 root wheel 240931640 21 Οκτ 00:25 root.20101020
-rw-r--r-- 1 root wheel 563447860 20 Οκτ 22:27 tmp.20101020
-rw-r--r-- 1 root wheel 22777054676 20 Οκτ 20:08 usr.20101020
-rw-r--r-- 1 root wheel 4975268576 20 Οκτ 22:07 var.20101020
pluto#
Four files created form the backup of the whole operating system. The backup files were created in the second mirror. During ZFS send there are some warning messages, but that is normal due to ad0 hard disk malfunction.
4. Replacing the old malfunctioned hard disc
Since we are done with the backup, it is time to replace the malfunctioned device. We need to avoid installation of a new operating system (since we are able to do that) and transfer all the ZFS Pools in the new device to avoid the rest discomfort.
a. Preparation of the new hard drive
There is no need to power off the computer for this step, nor to have an empty SATA connector on our motherboard. Copying ZFS Pools/Datasets from a hard drive to another requires the new hard disc to be partitioned, like the old one. That is the preparation we need to apply to the new device. We will repeat the steps we made during the first time we installed FreeBSD on ZFS. The difference is that we will perform these actions on the hard drive connected to USB. When we connect the new hard drive using a SATA to USB converter we will see some kernel messages:
Oct 23 10:43:21 pluto kernel: ugen4.2: at usbus4
Oct 23 10:43:21 pluto kernel: umass0: on usbus4
Oct 23 10:43:21 pluto kernel: umass0: SCSI over Bulk-Only; quirks = 0x4000
Oct 23 10:43:23 pluto kernel: umass0:2:0:-1: Attached to scbus2
Oct 23 10:43:23 pluto kernel: da0 at umass-sim0 bus 0 scbus2 target 0 lun 0
Oct 23 10:43:23 pluto kernel: da0: Fixed Direct Access SCSI-2 device
Oct 23 10:43:23 pluto kernel: da0: 40.000MB/s transfers
Oct 23 10:43:23 pluto kernel: da0: 1430799MB (2930277168 512 byte sectors: 255H 63S/T 182401C)
It is clear from these messages that the system uses the name da0 to access the newly connected hard disc. Caution is needed when writing the name of the drive, because it is very easy to mistype it to ad0 which is the old malfunctioned one! The partitioning is made in the following way:
pluto# gpart destroy # may fail
pluto# gpart create -s gpt da0 # Create gpt scheme on external hard disc
pluto# gpart add -s 256K -t freebsd-boot da0 # Create the boot loader's partition
pluto# gpart add -s 4G -t freebsd-swap da0 # Do not label it yet
The two first partitions are created, one for bootcode and another for swap memory. The latter does not have a label yet, because the name we want to give to it is the same as the one already in use by the system. To write the boot code we must execute the following command:
pluto# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 da0
pluto#
If the command fails with a message that there is already a boot code written in the Boot Record then we just omit the command line switch -b, meaning:
da0 has bootcode
pluto# gpart bootcode -p /boot/gptzfsboot -i 1 da0
pluto#
It is very difficult to remember the exact size of the partitions disk0, disk1 and disk2 of the base hard drive (the malfunctioned one), it is a very good approach to ask gpart to show us:
pluto# gpart list ad0
Geom name: ad0
fwheads: 16
fwsectors: 63
last: 2930275021
first: 34
entries: 128
scheme: GPT
Providers:
1. Name: ad0p1
Mediasize: 262144 (256K)
Sectorsize: 512
Mode: r0w0e0
rawtype: 83bd6b9d-7f41-11dc-be0b-001560b84f0f
label: (null)
length: 262144
offset: 17408
type: freebsd-boot
index: 1
end: 545
start: 34
2. Name: ad0p2
Mediasize: 4294967296 (4.0G)
Sectorsize: 512
Mode: r1w1e1
rawtype: 516e7cb5-6ecf-11d6-8ff8-00022d09712b
label: swap0
length: 4294967296
offset: 279552
type: freebsd-swap
index: 2
end: 8389153
start: 546
3. Name: ad0p3
Mediasize: 495790956544 (462G)
Sectorsize: 512
Mode: r1w1e2
rawtype: 516e7cba-6ecf-11d6-8ff8-00022d09712b
label: disk0
length: 495790956544
offset: 4295246848
type: freebsd-zfs
index: 3
end: 976730865
start: 8389154
4. Name: ad0p4
Mediasize: 500107862016 (466G)
Sectorsize: 512
Mode: r1w1e2
rawtype: 516e7cba-6ecf-11d6-8ff8-00022d09712b
label: disk1
length: 500107862016
offset: 500086203392
type: freebsd-zfs
index: 4
end: 1953504033
start: 976730866
5. Name: ad0p5
Mediasize: 500106745856 (466G)
Sectorsize: 512
Mode: r1w1e2
rawtype: 516e7cba-6ecf-11d6-8ff8-00022d09712b
label: disk2
length: 500106745856
offset: 1000194065408
type: freebsd-zfs
index: 5
end: 2930275021
start: 1953504034
Consumers:
1. Name: ad0
Mediasize: 1500300828160 (1.4T)
Sectorsize: 512
Mode: r4w4e11
pluto#
The needed partitions are labelled disk0, disk1 and disk2, meaning those with index numbers 3, 4 and 5, respectively. In every block presented there are two values we need to consider. The first one is start and the second one is end. To figure out the size we need to pass to the following commands we must calculate end-start+1. For the showed partitions we have:
| Label |
Start |
End |
Calculated Length |
| disk0 |
8389154 |
976730865 |
976730865 -8389154 +1 = 968341712 |
| disk1 |
976730866 |
1953504033 |
1953504033 -976730866 +1 = 976773168 |
| disk2 |
1953504034 |
2930277134 |
2930277134 -1953504034 +1 = 976773101 |
Knowing those values we can create the new partitions with exactly the same size as the old ones. The size we calculated is in number of blocks. The labels of the new partitions will be main0, main1 and main2, respectively (we cannot use the same labels as the ones already used by the system). For the last partition there is no need to specify size value. The system will occupy the rest of the free space of the device, without leaving unused space.
pluto# gpart add -s 968341712 -t freebsd-zfs -l main0 da0
pluto# gpart add -s 976773168 -t freebsd-zfs -l main1 da0
pluto# gpart add -t freebsd-zfs -l main2 da0
pluto#
Now the new hard disc drive is ready to replace the old malfunctioned one. The only step left is to copy the data.
b. Replacing the ZFS pools
ZFS has unbelievable power to administer its filesystems. It can even replace its pools! This is the ability we will use now:
pluto# zpool replace zroot gpt/disk0 gpt/main0
pluto# zpool status zroot
pool: zroot
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scrub: resilver in progress for 0h4m, 1,15% done, 6h15m to go
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
replacing ONLINE 0 0 0
gpt/disk0 ONLINE 259 0 0
gpt/main0 ONLINE 0 0 0 1,23G resilvered
errors: No known data errors
pluto#
The first command (replace) starts a process called resilvering. Of course, this process takes a lot of time. ZFS Subsystem does whatever is needed in the background, leaving the user to perform other tasks as usual. The only difference is that the performance of the computer drops, something that is already true due to the malfunctioned hard disc. The second one (status) can be executed from time to time to see the status of the resilvering process. When resilvering of the pool finishes we can start the resilvering of the two other ZFS Pools. Use the following commands:
pluto# zpool replace Common1 gpt/disk1 gpt/main1 #wait until this process is finished and then...
pluto# zpool replace Common2 gpt/disk2 gpt/main2 #again, wait until the end of the process
pluto#
Finally, when all the resilvering of all available pools finishes, the new hard disc will contain all the data that could be recovered from the old one. ZFS subsystem will use the new pools that are now in the new hard drive. Time to power off the machine and replace the old malfunctioned device with the new one in the PC box.
5. WE ARE NOT DONE!!!!
OOOPS! What happened? Why the system does not boot up?
While trying to boot our machine with the new drive, just after the loader's menu we stay in mountroot with the notification that zfs:zroot could not be mounted! Whatever we do the system cannot boot our operating system. This makes us think that something is wrong with zpool.cache file. This file, in short, contains information for the structure of the ZFS pools and it is very important for the correct boot of the system. During the resilvering process this file was copied from the old hard disc, but its contained information describe the pools of the old device. So, these information do not match the new pools.
I believe you noticed that the labels of the gpt partitions are not the same as those applied in the old hard disc device but this is not a problem for the ZFS subsystem as we will see shortly. ZFS knows its pools by a unique ID that it applies to the pools at the time of their creation.
a. Changing of the labels of gpt partitions
In this procedure described here, the only mandatory part is to give swap partition the label that had in its previous device. This is convenient for us to avoid altering the /etc/fstab file. The rest are not necessary to be applied. We just restore the old labels for clarity, because we were used to them and not for any other reason. We will proove it here. The following procedure demands us to boot from livefs and use the Fixit console. There, we can check the state of the ZFS Pools.
Fixit# #lets load the zfs subsystem
Fixit# kldload /mnt2/boot/kernel/opensolaris.ko
Fixit# kldload /mnt2/boot/kernel/zfs.ko
Fixit# export LD_LIBRARY_PATH=/mnt2/lib
These commands must be executed every time we use Fixit console to be able to use the ZFS filesystem and access our ZFS Pools. Time for the pools check:
Fixit# zpool import
pool: Common1
id: 16786791901886102938
state: ONLINE
action: The pool can be imported using its name or numeric identifier
config:
NAME STATE READ WRITE CKSUM
Common1 ONLINE 0 0 0
mirror ONLINE 0 0 0
gpt/main1 ONLINE 0 0 0
gpt/Mirror1 ONLINE 0 0 0
errors: No known data errors
pool: Common2
id: 2880185314831596717
state: ONLINE
action: The pool can be imported using its name or numeric identifier
config:
NAME STATE READ WRITE CKSUM
Common2 ONLINE 0 0 0
mirror ONLINE 0 0 0
gpt/main2 ONLINE 0 0 0
gpt/Mirror2 ONLINE 0 0 0
errors: No known data errors
pool: zroot
id: 1188189039061593219
state: ONLINE
action: The pool can be imported using its name or numeric identifier
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
gpt/main0 ONLINE 0 0 0
errors: No known data errors
Fixit#
Here we can see that the gpt partitions used by the pools are the correct ones. So, it is not really necessary to change their labels. Also, observe the id number. This is the unique number we mentioned earlier.
To change the gpt labels we have to use the following commands:
Fixit# gpart modify -i 2 -l swap0 ad0 #label the swap partition as swap0
Fixit# gpart modify -i 3 -l disk0 ad0
Fixit# gpart modify -i 4 -l disk1 ad0
Fixit# gpart modify -i 5 -l disk2 ad0
The biggest problem we have on zpool.cache file creation is that the pools must be imported normally and not using altroot. This forbids us from using -R command line switch in import command. And this in turn brings us more trouble because zroot, when mounted, sits over the already existed Fixit system and replaces everything, and the file we need is copied from a system before we use it! Wrong file! We have to find a solution to have the correct zpool.cache file and this is done in two steps. First we must import zroot using altroot to be able to set the mountpoints.
Fixit# zpool import -fR /zroot zroot
Fixit# zpool import -f Common1
Fixit# zpool import -f Common2
Fixit# zfs unmount -a
Fixit# zfs set mountpoint=none zroot
Fixit# zpool export Common2
Fixit# zpool export Common1
Fixit# zpool export zroot
Fixit#
What we achieved with this is that the system does not complain when we import the pools, warning us that we need to use -f option and, second, zroot's main filesystem does not automatically get mounted, so it does not replace the files of Fixit console. Now, the new problem is that /boot/zfs directory of zroot is not available so we can not write any file into it.
To be able to create zpool.cache, the directory /boot/zfs must be existed. This is not true in the Fixit console so we have to create the directory in question by ourselves:
Fixit# mkdir /boot/zfs
Fixit#
zpool.cache now will be created automatically when we import the pools. So:
Fixit# zpool import zroot
Fixit# zpool import Common1
Fixit# zpool import Common2
Fixit#
At that point /boot/zfs/zpool.cache file is created with the valid information that ZFS system needs to be operative. The only thing left is to copy this file into another part of zroot that is already accessible. The place we choose is the /tmp directory. After the copy we will unmount the filesystems and restore the mountpoint we altered earlier.
Fixit# cp /boot/zfs/zpool.cache /tmp
Fixit# zfs unmount -a
Fixit# zfs set mountpoint=/ zroot
Fixit# zpool export Common2
Fixit# zpool export Common1
Fixit# zpool export zroot
Now we are in position to copy the new zpool.cache in its correct place in zroot and to restore th final mountpoint as it should be for the system to get propperly boot-up.
Fixit# zpool import -fR /zroot zroot
Fixit# zpool import -f Common1
Fixit# zpool import -f Common2
Fixit# cp /zroot/tmp/zpool.cache /zroot/boot/zfs/
Fixit# zfs unmount -a
Fixit# zfs set mountpoint=legacy zroot
Fixit# reboot
.
.
.
If all things are done correctly after restarting, out FreeBSD will finally boot, without any problems from the new hard disc drive. Do not forget that we had a malfunctioned hard disc and its data could be corrupted making the operating system unusable...
To everybody who started to use this article and change a malfunctioned hard disc drive, I wish you good luck. May the source be with you!